Article Text

Abstract
Objectives The purpose of this study was to use easily obtained and directly observable clinical features to establish predictive models to identify patients at increased risk of stroke.
Setting and participants A total of 46 240 valid records were obtained from 8 research centres and 14 communities in Jiangxi province, China, between February and September 2018.
Primary and secondary outcome measures The area under the receiver operating characteristic curve (AUC), sensitivity, specificity and accuracy were calculated to test the performance of the five models (logistic regression (LR), random forest (RF), decision tree (DT), extreme gradient boosting (XGBoost) and gradient boosting DT). The calibration curve was used to show calibration performance.
Results The results indicated that XGBoost (AUC: 0.924, accuracy: 0.873, sensitivity: 0.776, specificity: 0.916) and RF (AUC: 0.924, accuracy: 0.872, sensitivity: 0.778, specificity: 0.913) demonstrated excellent performance in predicting stroke. Physical inactivity, hypertension, meat-based diet and high salt intake were important prediction features of stroke.
Conclusion The five machine learning models all had good predictive and discriminatory performance for stroke. The performance of RF and XGBoost was slightly better than that of LR, which was easier to interpret and less prone to overfitting. This work provides a rapid and accurate tool for stroke risk assessment, which can help to improve the efficiency of stroke screening medical services and the management of high-risk groups.
- stroke
- epidemiology
- statistics & research methods
Data availability statement
Data are available upon reasonable request. The data presented in this study are available upon request from the corresponding author. The data are not publicly available due to privacy concerns.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Strengths and limitations of this study
The study used machine learning algorithms with some simple and readily available clinical features for rapid stroke prediction.
The study compared five different algorithms to find the best model, adding to the limited research on stroke risk prediction in China.
Data were collected from 51 483 participants in Jiangxi province using the multistage stratified random cluster sampling method.
The study was cross-sectional, which might have introduced some bias.
Generalisation of study findings to populations of different ages and outside China should be cautious.
Introduction
Stroke is the leading cause of death and disability worldwide.1 2 China is one of the countries with the heaviest stroke burden in the world, and the burden of stroke has been increasing in the past 30 years.3 Over 76% of strokes occur in those without a history of stroke, and mortality and disability associated with strokes significantly affect the lives of patients.4 The Global Burden of Disease Study reported that stroke incidence decreased by 12% in countries with practical strategies for preventing cerebrovascular risk factors and good health services in 1990–2010.5 Prevention of stroke and related risk factors is an essential priority for global public health, especially for low-income and middle-income countries, such as China.
Early stroke screening is an essential means for effective preventive measures. However, the limitations of stroke screening include expensive examination items and an immeasurable workforce. It is unrealistic to ask doctors to make wide-scale diagnoses of stroke using modalities such as ECG, CT and MRI of the brain. In addition, the lack of self-awareness in high-risk individuals makes them want to be tested only when there is a suspected cerebrovascular disease event. To reduce the incidence of stroke, it is vital to develop a simple and accurate method of screening for stroke.
Machine learning has received intense attention for its robust disease prediction capabilities due to its different classification techniques.6–8 Currently, most machine learning algorithms have been developed as predictive tools for the prognosis of stroke and the occurrence of stroke with other complications, such as using machine learning to predict stroke-associated pneumonia in Chinese patients with acute ischaemic stroke or the outcomes in acute stroke.9–11 In contrast, there is a lack of research on the construction of stroke risk prediction models, especially in China. Previous Western studies have assessed traditional risk factors (smoking, diabetes, etc). They have developed some risk algorithms to provide valid measures of absolute stroke risk in the general population of patients free of stroke or transient ischaemic attack, as shown by their performance.12–14 However, it remains questionable whether these models can be reasonably applied to Chinese or other Western populations. A well-known example is the Framingham Stroke Risk Score (FSRS).15 The FSRS was later modified, particularly for the Chinese population, but the predictive power of the modified model has not been satisfactory.16
The development of appropriate disease prediction algorithms is technically challenging. To date, many classical machine learning algorithms have been applied to create a risk assessment for stroke. Li et al17 used the generalised linear model, Bayes model and decision tree (DT) model to predict the risk of ischaemic stroke and other thromboembolisms in people with atrial fibrillation. Zhang et al18 employed a variety of filter-based feature selection models to improve the ineffective feature selection in existing research on stroke risk detection. Yu et al19 developed a simple, convenient model to predict the risk of stroke among middle-aged and elderly Chinese adults using retrospective cohort datasets. Nevertheless, the sample size is relatively small for developing a prediction model, and the only variables used to build the model are sex, age, hypertension and total cholesterol (TC). Li et al20 developed a logistic regression (LR) model, naïve Bayesian model, Bayesian network model, DT model, neural network model, random forest (RF) model, bagged DT model, voting model and boosting model with DTs to improve stroke risk level classification methods in China. In their study, the outcome of the prediction model was stroke-free individuals at different risk levels determined by the National Stroke Center’s screening and intervention project rather than patients who had a stroke. These studies have performed well in stroke prediction, but they cannot fully address the practical issues facing population-level efforts to prevent stroke, especially in China. Therefore, we aim to establish a machine learning-based prediction model to predict stroke occurrence in the population using a sizeable Chinese population and easily obtained and directly observable clinical features.
Materials and methods
Study population
This study was supported by the National Stroke Center’s screening and intervention project for individuals at high risk of stroke. A total of 51 483 participants (stroke: 18 435; stroke free: 33 048) were recruited in Jiangxi province, China, from February to September 2018. For stroke, we collected electronic health records from eight research centres selected by the National Stroke Center. Stroke was defined by the WHO clinical criteria for stroke.21 The controls were permanent residents without stroke who had lived in the investigation site for more than 6 months; they were all from the 14 counties (cities, districts) randomly selected by the multistage cluster sampling method in the catchment areas or nearby areas of the hospitals where cases were recruited. The stroke status was comprehensively judged and ruled out by the neurologist during the interview and investigation after they asked about the history of the stroke, assessed neurological symptoms and signs, and conducted auxiliary examinations.
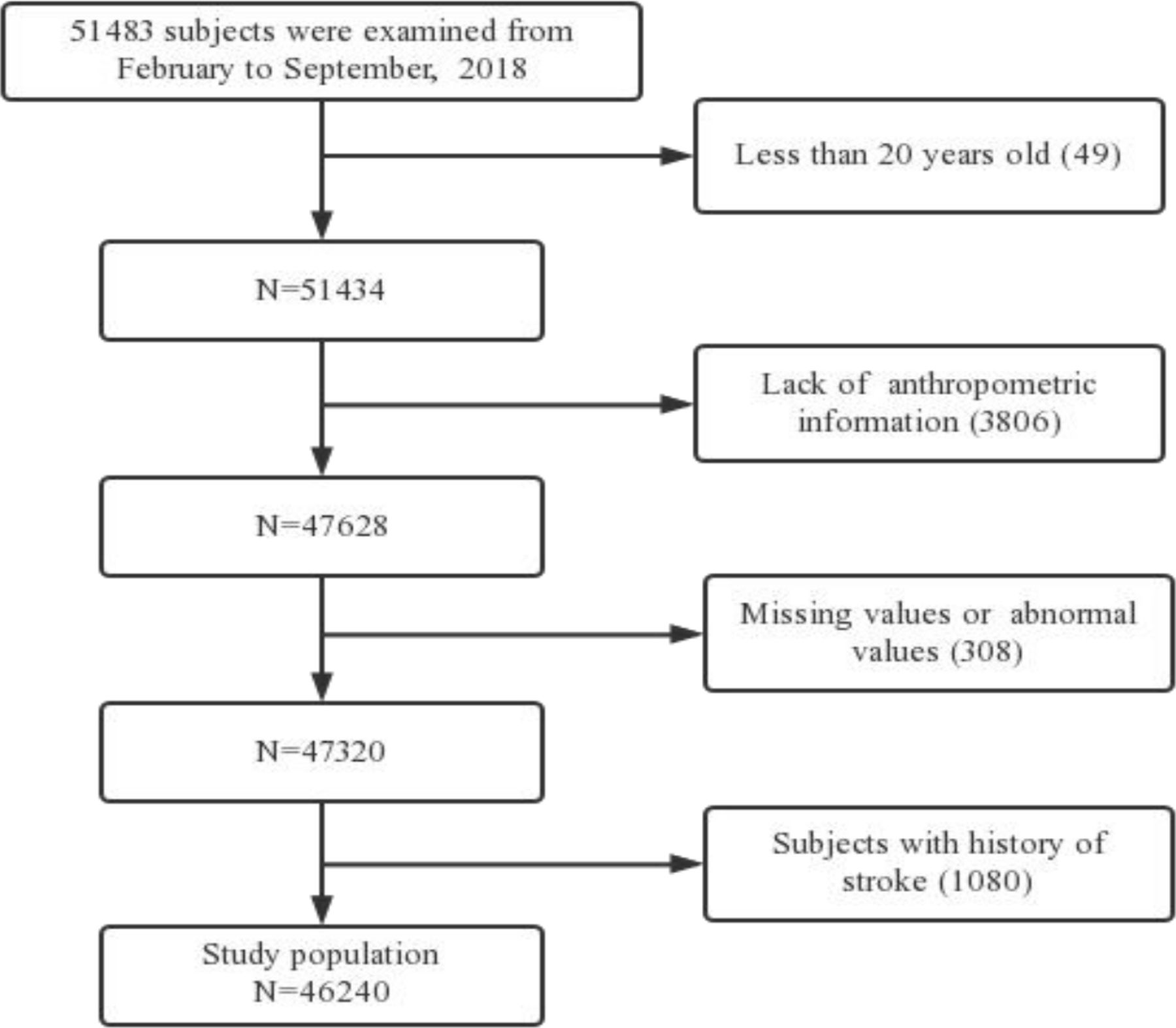
We prespecified 13 common independent features related to stroke that have been reported in some previous studies.22–25 During this process, we fully considered the economy, public acceptance, availability in practice and whether prevention can be achieved by interfering with these predictive factors. The China Stroke Primary Prevention Trial has shown that a high homocysteine concentration increases the risk of stroke.26 Eventually, the 13 features included basic predictors (age, sex and area), recognised significant risks (hypertension, smoking, diabetes mellitus, dyslipidaemia and physical inactivity), some modifiable risk factors and characteristics of interest (alcohol intake, high salt intake, meat-based diet, cardiac causes and high homocysteine). Among 51 483 records, a total of 5243 records were excluded. The exclusion criteria were as follows: less than 20 years old; lack of anthropometric information; missing values or abnormal values; and patients with a history of stroke. Finally, a total of 46 240 records were included in this study, as shown in figure 1.

Flow diagram of the study population selected from 8 research centres and 14 counties (cities, districts) in Jiangxi, China.
Data collection
Thirteen variables were included in this study. Cardiac disease was defined as abnormal ECG results or a history of atrial fibrillation, cardiomyopathy, heart failure, ischaemic heart disease, rheumatic heart disease or valvular disease diagnosed by a doctor in secondary or higher hospitals. Hypertension was defined as having a history of being diagnosed with hypertension by a secondary or higher hospital or blood pressure (mean of three measurements) of 140/90 mm Hg or higher. Blood pressure was measured at the time of admission. Diabetes was defined as a history of diabetes or a fasting blood glucose concentration greater than 7.0 mmol/L at the first encounter. Smoking status was defined as cumulative smoking for more than 6 months in a lifetime (current smoking and former smoking). Alcohol intake was classified as never, low or moderate intake and high (more than three times a week and 100 mL each time) intake. Physically active individuals were defined as being involved in moderate or strenuous activity three times or more for 0.5 hours or more per week or those engaged in moderate or severe physical labour. High salt intake and a meat-biased diet were defined by self-reported daily diet preference for salty taste and appreciation for meat, respectively. For obesity, we assessed body mass index (BMI). Individuals with BMI≥30 were defined as obese.24 Dyslipidaemia was defined according to the Chinese guidelines for the prevention and treatment of dyslipidaemia in adults as follows27: triglycerides≥2.26 mmol/L, TC≥6.22 mmol/L, low-density lipoprotein cholesterol≥4.14 mmol/L and high-density lipoprotein cholesterol<1.04 mmol/L. According to the WHO standard, the average level of homocysteine for healthy adults is 5–15 µmol/L, with a homocysteine level>15 µmol/L representing high homocysteine.28 The research patients were classified into urban and rural populations based on their areas of residence.
Patient and public involvement
This research was performed without patient involvement. Patients were not invited to comment on the study design or contribute to the writing or editing of the paper.
Feature preprocessing
The χ2 test and Student’s t-test were used for discrete and continuous parameters, respectively. For the independent features of stroke, multivariate LR analysis with backwards stepwise selection was used to calculate the OR with 95% CI. All variables were tested for correlation with each other.
Construction of machine learning models
In this study, we used five popular machine learning algorithms to predict the probability of a binary outcome (stroke or stroke free): LR,29 RF,30 DT,31 gradient boosting DT32 and extreme gradient boosting (XGBoost).33 First, we randomly split our dataset into two groups: the training sets (75%) for machine learning model development and the validation sets (25%) for performance evaluation. Second, we selected the ranges of hyperparameters to find the best prediction model for each machine learning model. According to the machine learning algorithms, we created a machine learning-based mortality prediction model with hyperparameters for predicting stroke occurrence in the population, which completes the range fitness through grid search using training data. Then, it is evaluated by 10-fold cross-validation. Third, when several hyperparameter combinations were optimal and the choice affected the model’s efficiency, we selected the parameter combination that led to the highest efficiency. More details about the features used and their parameter combinations in the models are shown in table 1. Fourth, each machine learning-based model employed the best hyperparameters and was evaluated by the validation sets. The area under the receiver operating characteristic curve (AUC), corresponding sensitivity, specificity and overall accuracy were applied to compare the predictive power of machine learning models; the closer the AUC was to 1, the better the classification model performed. The calibration curve was used to show the agreement between the predicted and observed risks of the five models. All variables were tested for correlation with each other, and a heatmap was generated with R (V.4.0.3, R Foundation for Statistical Computing). The R packages ‘polycor’ and ‘ggplot2’ were used for correlation analysis; the other statistical analyses were performed with Python (V.3.8, Python Software Foundation). All the results of the models we used in this study could be reproduced by using a fixed random seed.
The choice of hyperparameters for each model
Results
Demographic features
A total of 46 240 records (21 095 women and 25 145 men) were selected for this analysis, which included 14 360 records with stroke and 31 880 records without stroke. The average ages were 66.31±12.17 years for patients who had a stroke and 60.64±11.23 years for normal patients. The characteristics of the participants are presented in table 2.
Characteristics of variables in stroke and stroke-free groups
Univariate and multivariate LR analyses of stroke
In univariable analysis, sex, age, cardiac causes, hypertension, diabetes mellitus, smoking, alcohol intake, physical inactivity, high salt intake, meat-based diet, dyslipidaemia and high homocysteine were all significantly associated with stroke in Jiangxi province (p<0.001). In contrast, there was no significant difference between stroke and stroke-free patients in terms of whether they lived in urban or rural areas. In multivariate LR analysis (table 3), all parameters were included except for area. The results showed that except for women (OR 0.534, 95% CI 0.501 to 0.569), all the other parameters were independent positive predictors of stroke.
Univariate and multivariate logistic regression analysis of variables in predicting stroke
Performance of machine learning algorithms
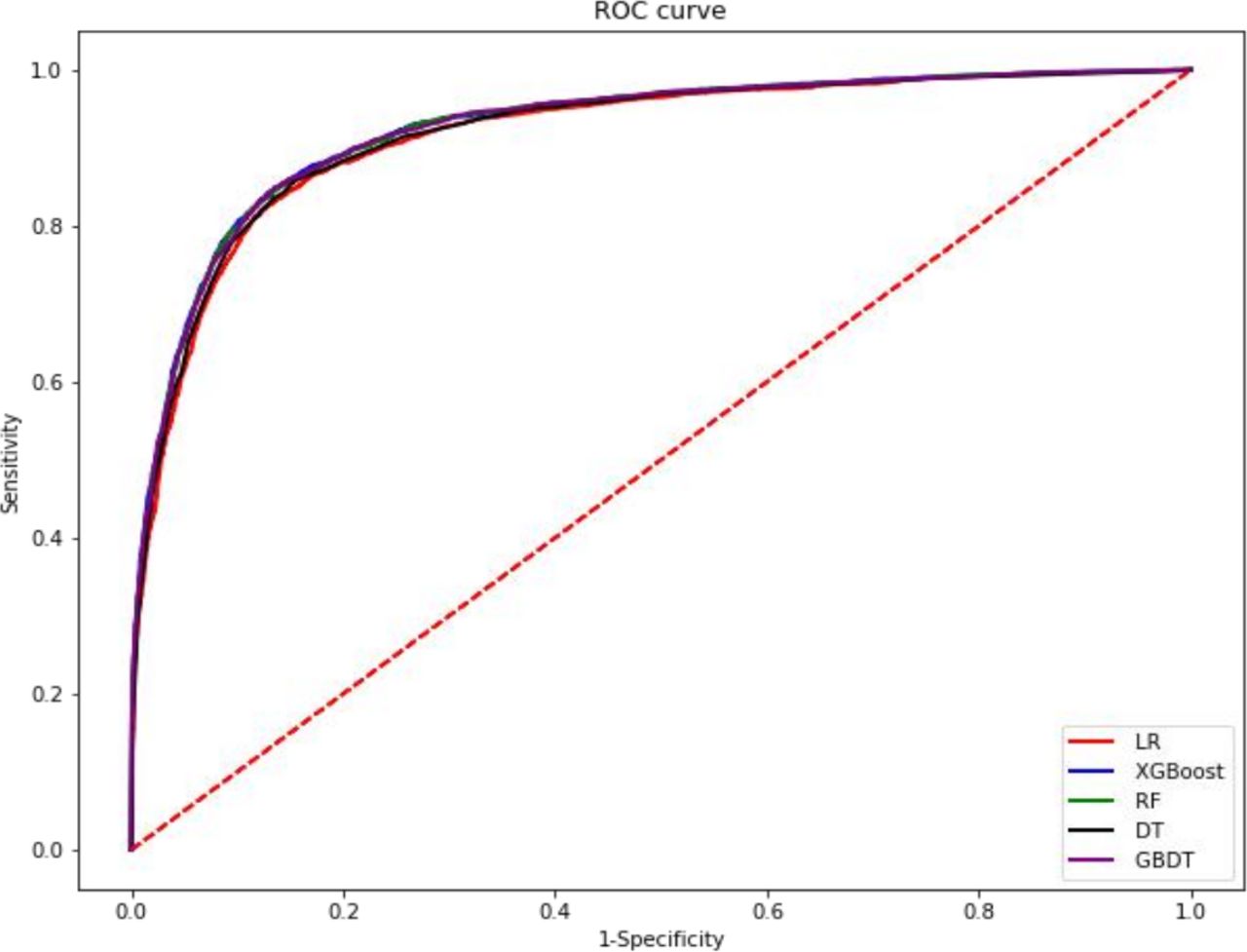
Comparisons of the performance of prediction among the five machine learning algorithms models in validation sets are detailed in table 4 and figure 2. The differences between these curves were slight. The performance of XGBoost (AUC: 0.924, accuracy: 0.873, sensitivity: 0.776, specificity: 0.916) and RF (AUC: 0.924, accuracy: 0.872, sensitivity: 0.778, specificity: 0.913) was the best in predicting stroke.
Predictive performance comparison of the five types of machine learning algorithms in the validation sets

Performance characteristic curves for five models (logistic regression (LR), random forest (RF), decision tree (DT), extreme gradient boosting (XGBoost) and gradient boosting decision tree (GBDT)). ROC, receiver operating characteristic.
Figure 3 presents a graphical representation of calibration, showing agreement between the predicted and observed risk of the five models. The figure demonstrates that the calibration curves of all models are close to perfect calibration.

Calibration curve showing the agreement between predicted (x-axis) and observed (y-axis) risk of five models. The prediction probability of stroke is divided into 10 bins on average. The diagonal dotted line represents a perfect prediction by an ideal model. DT, decision tree; GBDT, gradient boosting decision tree; LR, logistic regression; RF, random forest; XGBoost, extreme gradient boosting.
All variables were tested for correlation, as shown in figure 4. There was a significant correlation between sex and smoking (correlation coefficient>0.8).

Results of correlation analysis between all variables.
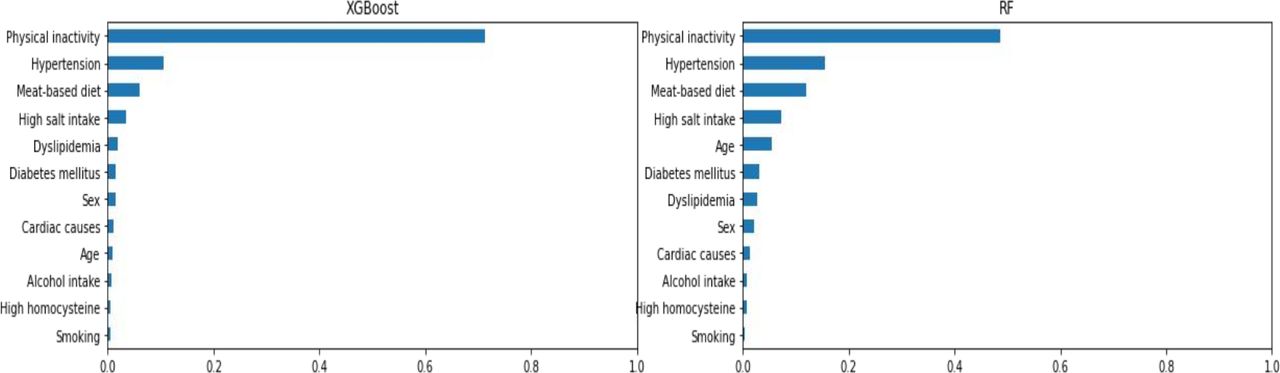
Moreover, according to the information gain values of the five models, the relative importance of variables in XGBoost and RF is shown in figure 5. We can see there were general evidence trends: physical inactivity contributed the most to stroke, followed by hypertension, a meat-based diet and high salt intake.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Relative importance ranking of each input variable for prediction of stroke extreme gradient boosting (XGBoost) and random forest (RF).
Discussion
In this study, we employed machine learning algorithms to examine the performance of five classifiers and 12 non-invasive and easily obtained clinical features for the rapid and accurate identification of individuals who had a stroke. All models in our study showed very excellent predictive performance, especially RF and XGBoost. This suggests that using machine learning algorithms with some simple and readily available clinical features for rapid stroke prediction is reasonable and feasible. This method is especially suitable for low-income or middle-income areas with heavy stroke burdens, such as China.
RF and XGBoost seem to be the machine learning algorithms of choice in most similar studies.10 34–36 In the literature, we found that advanced machine learning techniques such as RF and XGBoost modelling can improve the utilisation of information in analytical databases and enable the development and validation of predictive models with better performance.7 RF and XGBoost showed a considerable degree of predictive power. The RF model was better than XGBoost in accurately detecting patients who had a stroke, whereas the XGBoost model was good at identifying more stroke-free patients. During the training process, the hyperparameters of each algorithm (except for LR) were tuned. We decided not to tune the parameters of the LR model to keep the model specification as simple as possible for comprehensibility. The grid search values were adjusted to optimise the performance of the models. In this study, too many DTs (n=291) in RF required a huge training space and time. In addition, as a black-box model, it cannot control the internal operation of the model for RF, which is not conducive to the interpretation of the model. It was also challenging to avoid complex operating costs for XGBoost. It is worth noting that the classical model, such as LR, also shows solid predictive performance compared with these complex machine learning algorithms. The LR model is easier to use and interpret and less prone to overfitting, but it is sensitive to independent variable multicollinearity. In addition, the correlation analysis results indicated a significant correlation between sex and smoking. However, we still included them in this study because we are more concerned about the predictive power for stroke of the models rather than reporting the impact of stroke.
We have provided more details of similar studies in recent years in table 5. Compared with other studies,14 19 20 37–41 the models we used have stronger prediction and discrimination performances with higher AUCs, which may be due to the inclusion of more variables in this study. Many machine learning models are sensitive to imbalanced data. The patients we selected included a large number of patients who had a stroke from hospitals, which prevented the classification results from being affected by potential bias. We found that physical inactivity is the most predictive feature of stroke, whether we used the RF or XGBoost models. Physical inactivity is followed by hypertension, meat-based diet and high salt intake. Hypertension has always been considered to be the most important risk factor for stroke,22 42 which seems to deviate from our results. The results of a large-scale case–control study23 showed that physical inactivity rather than hypertension was the most important risk factor in China. This also indicates that each region should establish a prediction model with its own geographic and ethnic characteristics based on its own data.43 In addition, studies19 40 have reported that age was a significant risk predictor for stroke, whereas it was not highly predictive of stroke in our models. Age group may obscure the contribution of age to stroke in this study. Homocysteine was used as a new predictor to develop a predictive model for stroke. Our results suggest that high homocysteine may not show an important predictive ability for stroke. A meta-analysis reported44 that elevated homocysteine levels were associated with an increased risk for strokes in different subtypes, which indicated that these stroke risk prediction models built only for overall stroke (ischaemic and haemorrhagic stroke) may underestimate the importance of homocysteine levels for different subtypes of stroke, especially ischaemic stroke. The China Stroke Primary Prevention Trial has shown that high homocysteine concentration increases the risk of stroke. We included this feature because of interest and ease of detection. Our study showed that high homocysteine was an independent predictor of stroke and that the association with hypertension was not significant, so we retained this feature in the final model. It is a very interesting topic for reflection in future public health work as to whether we will consider a cost-effective or more streamlined version.
Summary of this study and other similar research findings
The trend in prediction models is to incorporate simplicity and non-invasiveness. In a resource-poor environment, the burden of stroke is disproportionately high.45 46 The model developed by laboratory testing is difficult to use. Several large-scale studies have demonstrated that far-reaching measures to prevent stroke must involve targeted lifestyle interventions.22–24 45
In this study, we used a real dataset of stroke cases from hospitals, and all the cases were diagnosed by doctors, which was more reliable than if the individuals were diagnosed by self-reporting. In addition, data from multiple centres would provide reliable predictive value on how our models identify stroke without selection bias. The models we developed are simple, non-invasive, cost-saving and time-saving, and easy to apply in scenarios other than the clinical setting. We have included enough clinical features to promote stroke screening and prevention in nonprofessional populations. However, some limitations of this study need to be acknowledged. First, this study did not distinguish between ischaemic and haemorrhagic strokes in the diagnosis of stroke. There are some notable differences in risk factors between ischaemic and haemorrhagic stroke.47 Therefore, more studies with the development of predictive models for ischaemic and haemorrhagic stroke need to be conducted. Second, the models are based on machine learning algorithms, so there may be some difficulties in clinical interpretation of the important features screened out by the models. Third, this is a study based on a province in China, so there may be gaps in population applicability, so it is necessary to include a broader population in future studies. Fourth, the prediction variables obtained retrospectively may leak information to the fitted models, which should be treated with caution during evaluation. The results should be confirmed in a prospective study. Fifth, the overall accuracy of our model in predicting stroke in the general population is likely to be overly optimistic.
Conclusion
In this study, we demonstrate that the 5 machine learning models developed by using 12 clinical features that are easily obtained and non-invasive all have good predictive and discriminative performance for stroke. The performance of these sophisticated models, such as RF and XGBoost, is slightly better than that of LR, which is easier to interpret and less prone to overfitting. This work provides a rapid and accurate stroke risk assessment tool that can help to improve the efficiency of stroke screening medical services and the management of high-risk populations.
Data availability statement
Data are available upon reasonable request. The data presented in this study are available upon request from the corresponding author. The data are not publicly available due to privacy concerns.
Ethics statements
Patient consent for publication
Ethics approval
This study involves human participants and was approved by Xuanwu Hospital Capital Medical University (no. 024 [2015]). Participants gave informed consent to participate in the study before taking part.
Acknowledgments
We would like to thank the researchers who participated in this survey.
References
Footnotes
Contributors YQ: Conceptualisation (lead), writing—original draft (lead), formal analysis (lead), writing—review and editing (equal). YW: Writing—original draft (lead), writing—review and editing (equal). SH: Conceptualisation (supporting), formal analysis (supporting), writing—review and editing (equal). WY: Methodology (lead), formal analysis (supporting), writing—review and editing (equal). YC: Conceptualisation (supporting), project administration (equal). YX: Data curation (equal), project administration (equal). XC: Investigation (qual), project administration (equal). JY: Writing—review and editing (equal). XC: Writing—review and editing (equal). SC: Conceptualisation (supporting), supervision (equal). HZ: Conceptualisation (supporting), supervision (equal). YQ is the lead study investigator. HZ is the guarantor.
Funding The study was supported by Natural Science Foundation of Jiangxi Province (20202BABL216044), National Natural Science Foundation of China (Grant No.: 81960618), Regional Project of National Natural Science Foundation of China (Grant No.: 82260388), Key projects of Jiangxi Provincial Department of Education (GJJ210118), Project of Jiangxi Provincial Health Commission (202130385) and Key projects of Jiangxi Provincial Administration of Traditional Chinese Medicine (2022Z017).
Competing interests None declared.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Provenance and peer review Not commissioned; externally peer reviewed.